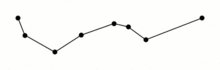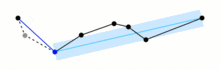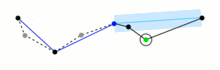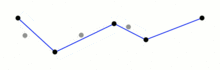
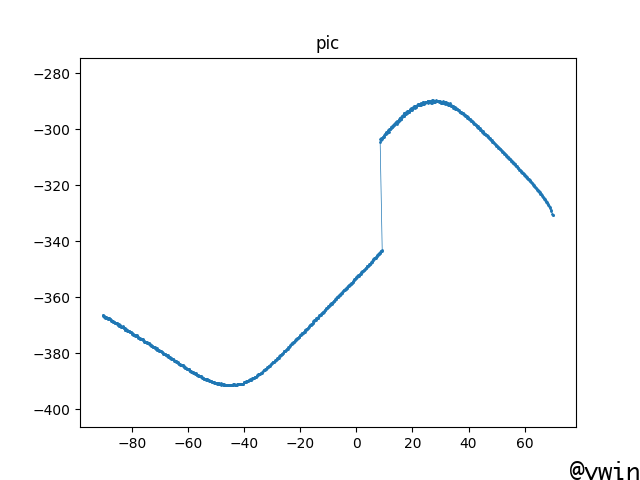
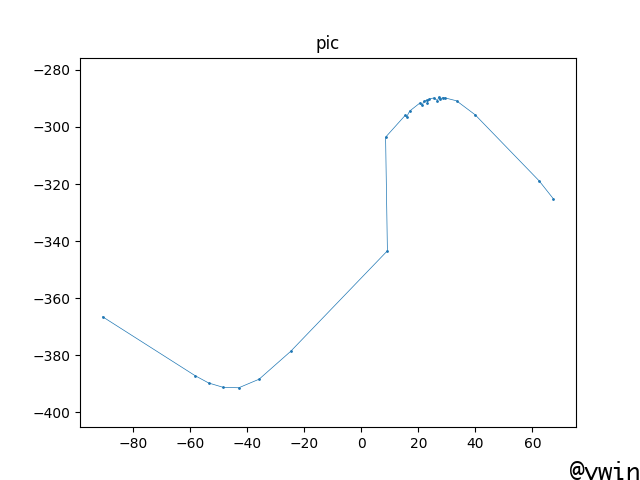
import math import re import matplotlib.pyplot as plt
defDPeucker(dataOrigin, epsilon=0.6): data = list() # to make sure that the datatype is list type instead of numpy list # print(type(dataOrigin)) if(type(dataOrigin) == type([])): print("the type is right") else: for i inrange(dataOrigin.shape[0]): data.append(list(dataOrigin[i])) # print(data) removeLabel = list() label_init = lineSegments(data, 0, len(data), removeLabel, epsilon) # from bigger to smaller to remove the redundant data, sort it and remove the repeat data. labelFinal = list() label_init.sort(reverse=True) for item in label_init: ifnot item in labelFinal: labelFinal.append(item) # remove the redundant point for i in range(len(labelFinal)): del data[labelFinal[i]] # get the point # print(data) if(type(dataOrigin) == type(np.array(0))): data = np.array(data) return data
defcalLinePara(start, end): # input parameters is two end points if(end[0] - start[0] != 0): k = (end[1] - start[1]) / (end[0] - start[0]) b = (end[0] * start[1] - end[1] * start[0]) / (end[0] - start[0]) if(end[1] - start[1] != 0): x_axis = -b / k else: x_axis = None else: k = None b = None# mean the paras is inexistence. x_axis = end[0] return (k, b, x_axis)
# figure out the distance from dot to line def dotToLIneDistance(point, k, b, a_axis): if k == Noneand b == None: distance = abs(a_axis - point[0]) else: distance = abs(k * point[0] - point[1] + b) / math.sqrt(k * k + 1) return distance
# recall itself to finish segments itself def lineSegments(listData, startLabel, endLabel, removeLabel, epsilon): # removeLabel is a list as a formal parameter, and will be changed by the function if((endLabel - startLabel) <= 1): return removeLabel else: k, b, x_axis = calLinePara(listData[startLabel], listData[endLabel-1]) distance = list() for i inrange(startLabel+1, endLabel): # print(dotToLIneDistance(listData[i], k, b, x_axis)) distance.append(dotToLIneDistance(listData[i], k, b, x_axis)) # print(distance) # print(max(distance)) if(max(distance) <= epsilon): # print(endLabel-1, startLabel) for i in range(startLabel+1, endLabel): # for i in range(endLabel-1,-1, int(startLabel)): removeLabel.append(i) else: middleLabel = distance.index(max(distance)) + startLabel + 1 lineSegments(listData, middleLabel, endLabel, removeLabel, epsilon) lineSegments(listData, startLabel, middleLabel, removeLabel, epsilon) return removeLabel
import math import re import sys from pathlib import Path
# use the dp algorithm to simplify the line. current_folder = Path(__file__).absolute().parent father_folder = str(current_folder.parent) sys.path.append(father_folder) import matplotlib.pyplot as plt import numpy as np from package.func import *